4. DataOps: Emerging powerful modular tooling
Data Science depends on good data engineering. Data is the differentiating factor in evolving powerful models and a new paradigm of composable data systems are coming to fruition to meet the demands of machine learning-driven businesses
Although many data scientists are eager to build and tune ML models, the reality is an estimated 70% to 80% of their time is spent toiling in the bottom three parts of the hierarchy — gathering data, cleaning data, processing data.
Making it easy for your team to work with a curated set of data, by combining modular components of a modern data-stack, will ease the iterative process of experimentation and allow for productionisation of workflows that scale more easily.
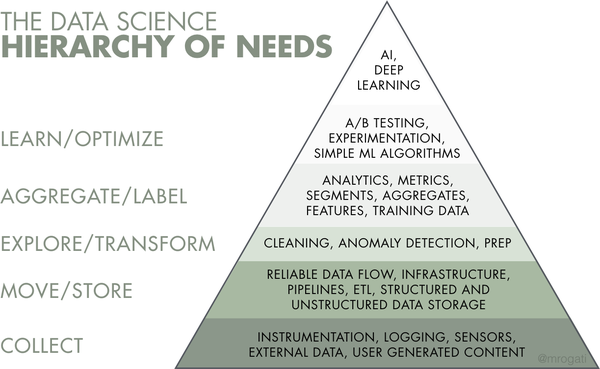
We are in a sweet-spot in terms of being able to harvest the fruits of years of effort from various opensource projects directed at making working with data at scale more efficient and less dependent on proprietary solutions. For those locked into vendors, it’s perhaps time to dispense with those relationships and avail of this new generation of performant tools.
- #4. DataOps Strategy: Embedding Data Everywhere (this one)
- #5. LLMs: Key Emerging Components of the AI Tech Stack
Recap So Far
By way of recap of this AI strategy blog-series, so far we have covered off skaffolding a strategy, planning through documentation, the importance of finding a relevant business-application for experimentation and ultimate productionisation, as well as the necessity of evolving a solid platform on which to be able to iterate on AI solutions, scale them, and weave them into the fabric of your business. We will continue that journey with two more blog-posts in this series, focusing initially on all things DataOps-related, before diving into the world of LLM-based application development and its promise, pointing to important lessons-learned so far from respected practitioners in this field.

What is DataOps?
It is critical to architect data thoughtfully for easy consumption and reuse; otherwise, scaling becomes challenging. The goal is to have clean, relevant, and available data (see Figure 2) so that agile teams can use it to make better decisions and build better data-enabled solutions.
Data volume, velocity, and variety require novel and automated ways to ‘operate’ this data. In accordance with software development, where DevOps is the de-facto standard to operate code, DataOps is an emerging approach advocated by practitioners to tackle data management challenges for analytics.
While there may be different definitions of what DataOps is, at its core it is about automation and observability. This includes automating the deployment of the data platform (and updates to the platform), as well as deployment and updates to the transform code that produces data products.
A key part of this automation is managing infrastructure for the data platform and logic for data transformations as version-managed code. In the same way, when deploying data transformation code, this code should be managed and deployed from a version-controlled code repository.
Key capabilities of a DataOps tool include:
Data Pipeline Orchestration: This automates, coordinates, and monitors data pipelines through a single integrated platform, simplifying the management of complex data flows. It handles connector management and workflow impact analysis and maintains audit logs. Can be thought of as ‘meta-orchestration’ of the code and tools acting upon the data.
Data Pipeline Observability: Optimizes pipelines by monitoring data quality, detecting issues, tracing data lineage, and identifying anomalies using live and historical metadata. This capability includes monitoring, logging, and business-rule detection.
Data Pipeline Test Automation: This tool supports QA runs, validation of business rules, management of test scripts, and execution of regression tests, ensuring the reliability of pipeline code.
Data Pipeline Deployment Automation: Automates version control, DevOps integration, release management, and change management approvals across data release cycles, following a continuous integration/continuous deployment (CI/CD) methodology.
Environment Management: This minimizes manual efforts by creating, maintaining, and optimizing pipeline deployment across different environments (development, testing, staging, production). It uses an infrastructure-as-code approach to consistently apply runtime conditions across all pipeline stages.
source: 2024 Gartner Market Guide to DataOps2

Composable Data Systems
Wes McKinney, the original author of the pandas library and a long-time advocate for better opensource data analysis tooling, penned an important blog4 at the end of 2023 that took stock of the culmination of many years of effort to arrive at a better, more composable tool-set.
While compute and networking speeds have soared over the past decade, data-analytics has lagged badly - the bottleneck often being CPU-bound, given a typical, up to now, need to serialize and de-serialize data moving between different ecosystem layers. Without a standardized solution for data interchange and in-memory computation, systems pay a steep penalty both in computational cost and development time to interoperate with each other. While libraries like pandas had been transformational for the data-analytics profession, it was generally accepted that it also had performance, scale, and memory-use problems. In McKinney’s words, pandas had to do everything for itself, and this was an enormous burden for a fully volunteer-based open source project.
Hence his involvement in various parallel projects to solve these problems, culminating in The Composable Data Management System Manifesto5 and a more detailed version articulated by Voltron Data (the driving force behind the open-source Ibis project) who have assembled a well-articulated technical series called The Composable Codex which brings a useful historical context to what has needed to happen to unleash better productivity around the data ecosystem, all enabled by open standards for exchanging and operating on data, allowing for more composable data systems being built that are modular, interoperable, customizable, and extensible (MICE). While we summarise some key concepts from this manifesto below, I would urge readers to read the Codex in full for a greater understanding of the importance of this seismic shift in thinking that will underpin how companies perform DataOps into the future.
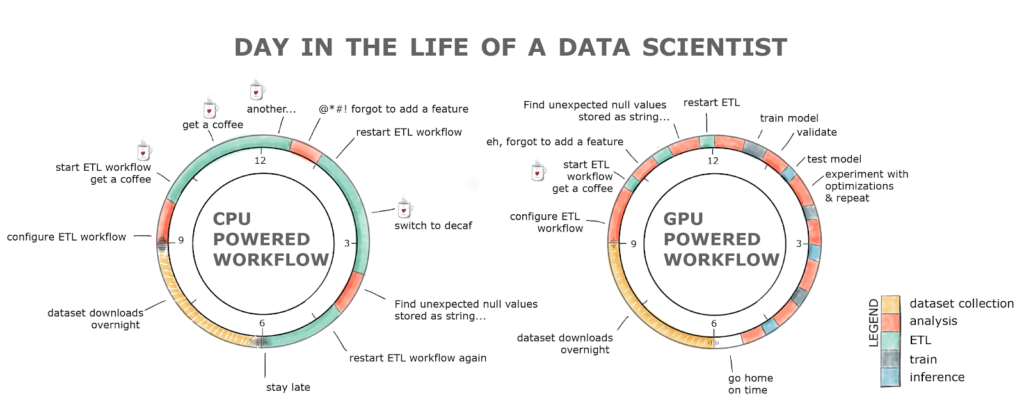
Even before the rise of LLMs, there was a real need for faster, more scalable, more cost-effective machine learning, as volumes of data grew exponentially. A before and after illustration of this shift to a better data ecosystem is probably well illustrated by NVIDIA’s tongue-and-cheek portrayal of a day in the life of a data-scientist, prior to GPUs. The data ecosystem changes are obviously more than just GPUs, but are probably best summarised as Accelerated Workflows, in general, enabled by tooling that operates on layers and as standards between those layers envisaged by the composable data system.
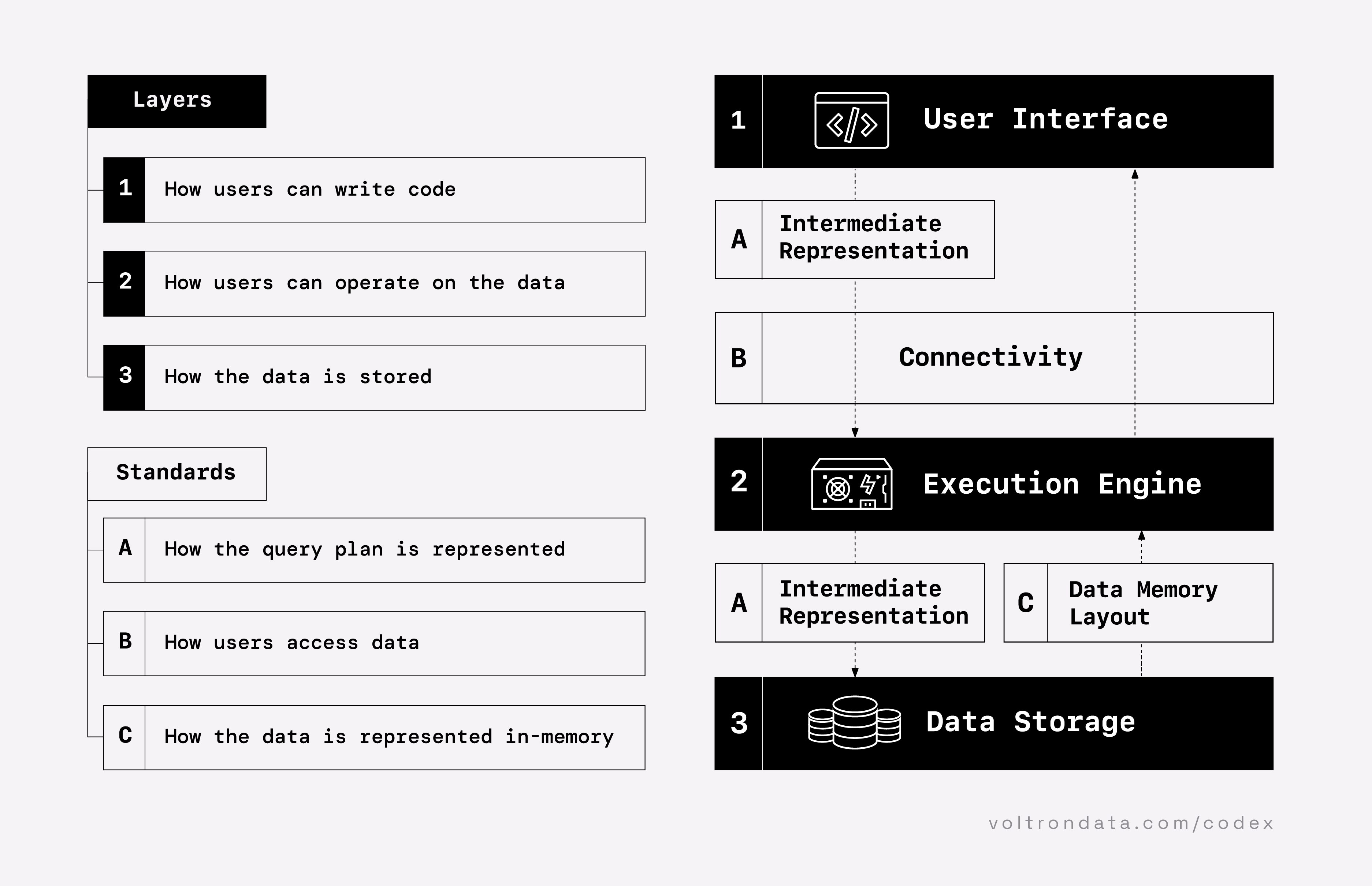
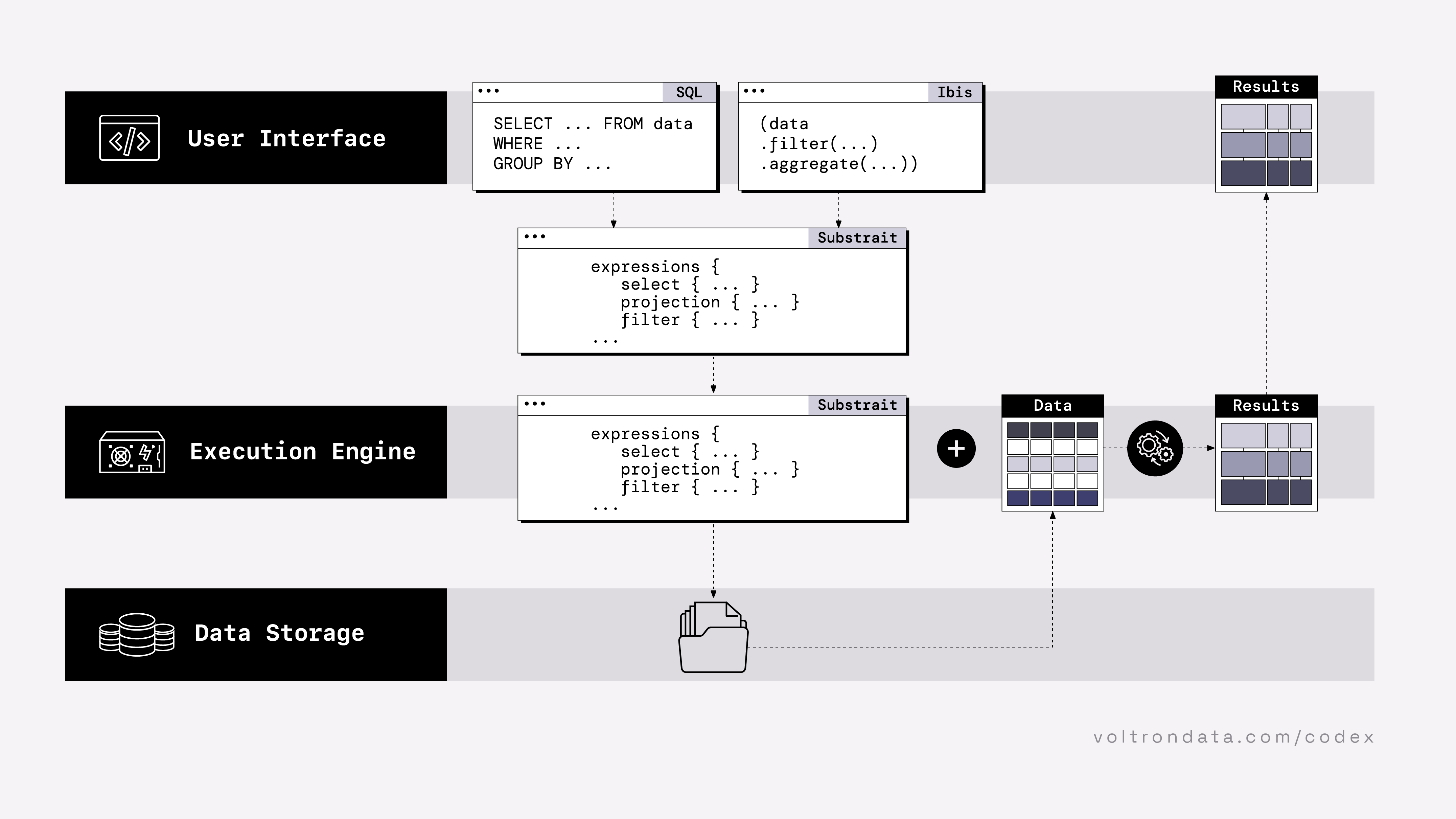
The Composable Codex has a concept of Layers (1, 2 and 3) and Standards (A, B and C).
Layers:
- User Interface [1] - Users interact with this UI in order to initiate operations on data. This is typically exposed as a language frontend or API.
- Execution Engine [2] - this engine performs operations on the data, as specified by users.
- Data Storage [3] - the layer that stores data that is available to users.
Standards:
- Substrait [A] - is a format standard for describing compute operations on structured data.
- ADBC (Arrow Database Connectivity) [B] - applications code to this API standard (like JDBC or ODBC), but fetch result sets in Arrow format.
- Arrow [C] - is focused on a standardized memory representation of columnar data.
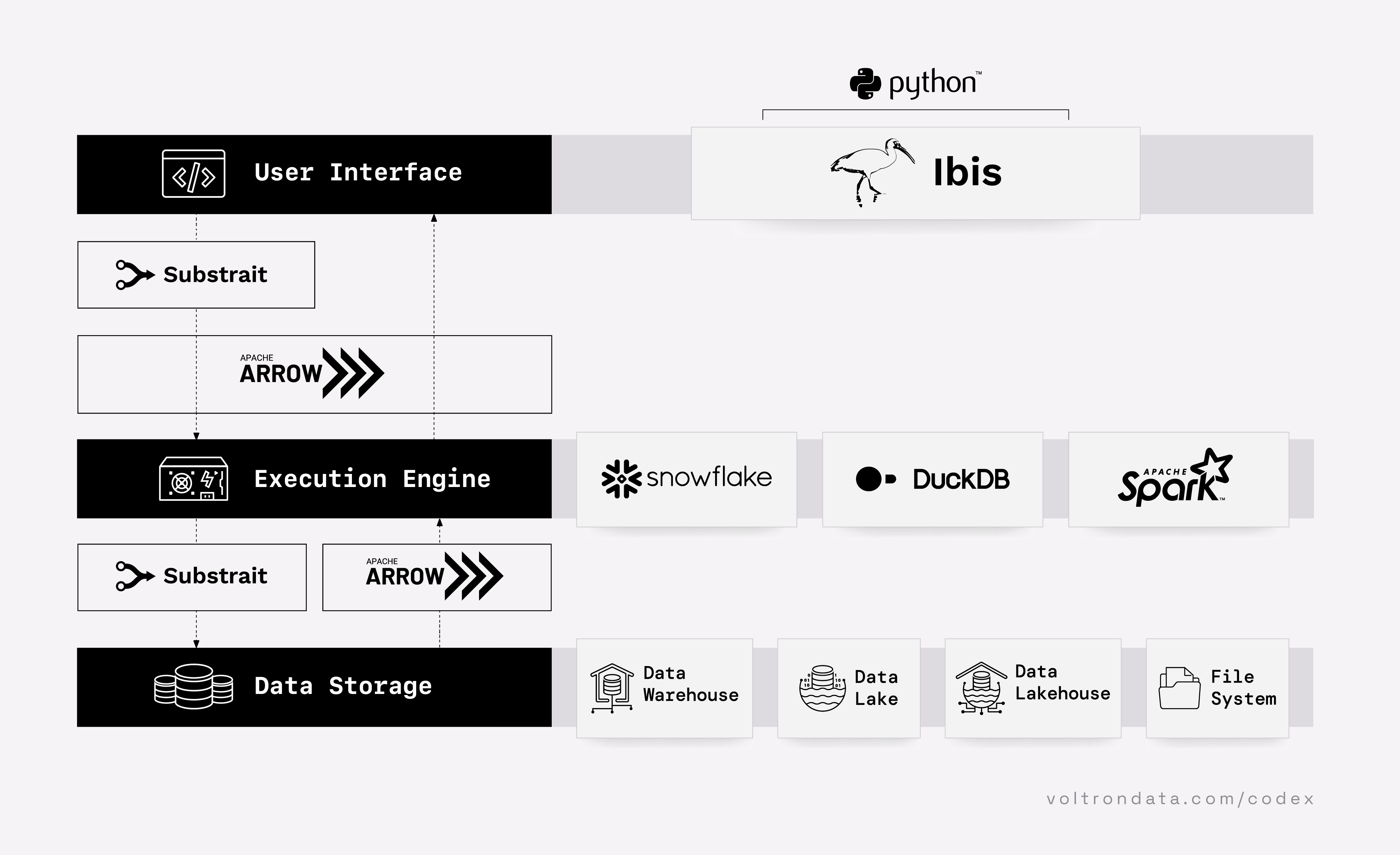
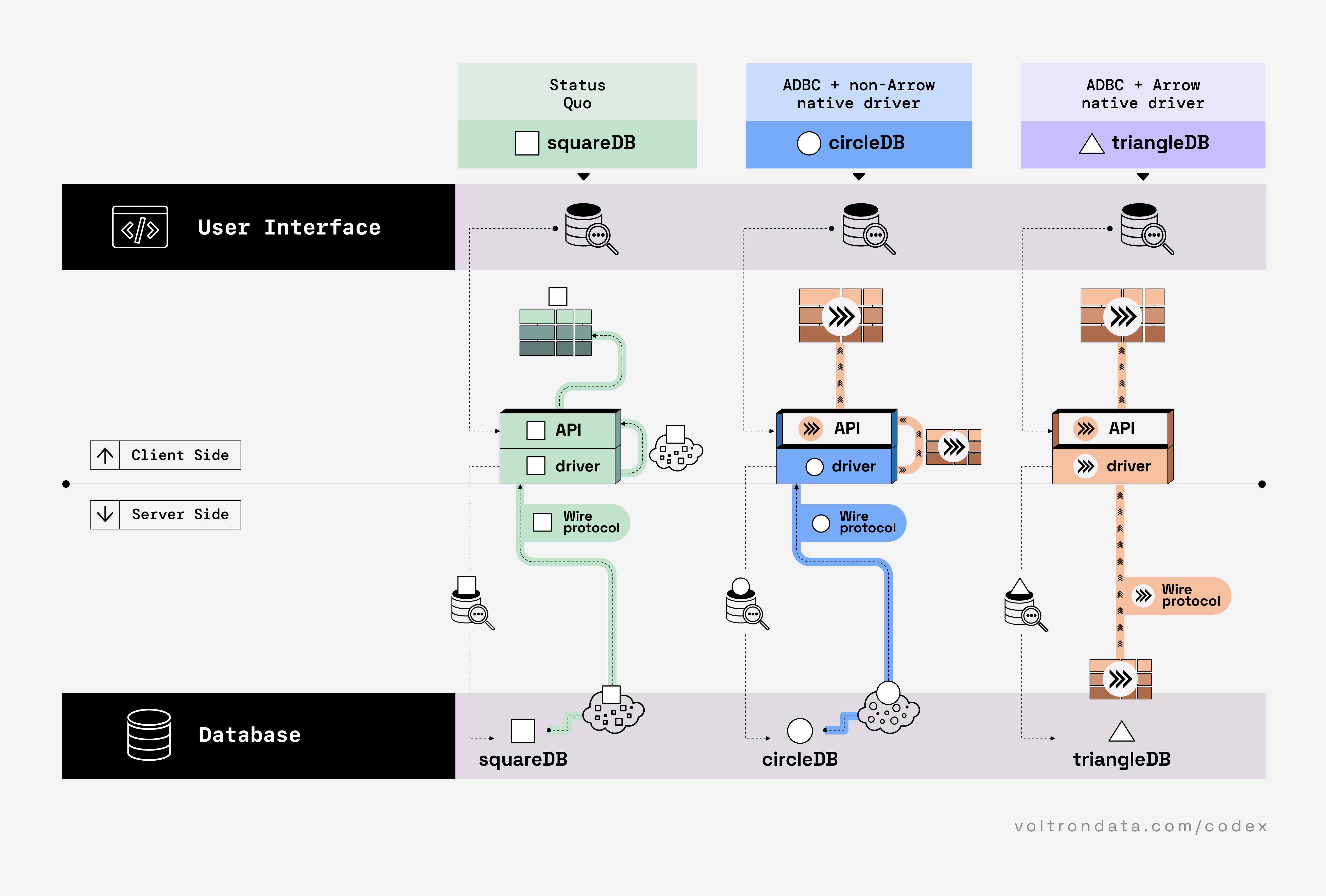
Cycling through the series of tabs on the left, The Composable Codex envisages a minimal viable data system as broken down into three main layers: UI, a query execution engine and a data-storage layer. Between those layers are standards, intended to ease friction between those layers and enhance interoperablitity for data (common data-structures), queries (common formats) and systems (serialization/data-interchange). On the second tab, we see projects like Ibis which works by decoupling the dataframe API (python) from the backend execution. Most backends support a SQL dialect, which Ibis compiles its expressions into, enabling queries (driving complex ETL) to be written once and work against multiple backends. Ibis uses Apache Arrow to provide a common data format for data interchange between Ibis and backends that is fast. Ibis is also able to compile queries to Substrait, an evolving cross-language serialization protocol. On the right-most tab, we see an evolution of status-quo systems (squareDB) towards using this fully-integrated modern data-tooling (triangleDB) resulting in vastly improved data-stack performance.
Convergence of technologies around Table Formats
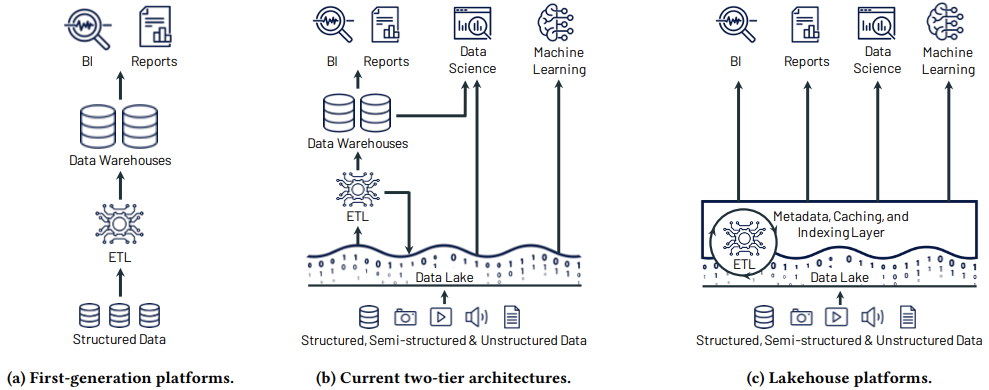
Building out shareable, yet robust, datasources across a company no longer needs to involve heavily-engineered solutions and expensive proprietary technology stacks. On the contrary, hosting data on cheap cloud-based object storage without losing its queryability has become mainstream with the emergence of what are called Data Lakehouses (Figure 8), a combination of the features of Data Lakes and Data Warehouses.
Integral to these new data systems are a series of open-standard Table Formats like hudi, iceberg and delta-lake, developed by big tech companies in recent years to solve their scaling needs. A Table Format is a data management layer that organises and tracks data files in a data lake as a logical table. These formats help manage datasets in data lakes, allowing for ACID transactions, time-travel queries, and efficient data retrieval.
According to Julien Le Dem11, who was involved in designing standards like Parquet and Arrow, the combination of blob storage, a columnar format, sorting, partitioning and table metadata enables efficient data access for a large array of OLAP (online analytical processing) use cases. When a query engine accesses data, it wants to minimize how much data needs to actually be scanned or deserialized from the storage format. Iceberg facilitates this by consolidating table metadata from the files that make a snapshot. We can decouple data access from the actual layout of the table, enabling storage optimization independently of the jobs accessing it.
With this new setup, you can own your data, store it once in your own bucket and connect various processing engines, open source or proprietary. There is no need to import or export data, trying out new tools is easy and data can be mutated without requiring additional coordination. Owning your data in cheap scalable storage in your own cloud account allows you to avoid vendor lock-in and removes silos. You are now free to optimize your cloud costs better than if storage becomes abstracted behind several vendors. If you’re wondering what all the fuss is about lately, this is what’s driving the adoption of Iceberg with Parquet to implement the Open Data Lake. Vendors are adopting this pattern not only because their customers do not appreciate vendor lock-in (they never did) but because there is enough momentum that there is an alternative and they will lose market share if they don’t.
Julien Le Dem, Nov. 2024, The Advent of The Open Data Lake12
Data-engineering tooling like dlt are tightly integrated with these formats, making it easier to build-out data resources using best-practices. Other open-source libraries like ibis can then bridge the data-science and data-engineering worlds by providing a unified querying experience across diverses backends, enabling data processing without platform-specific rewrites.
Supporting different open-source file formats (eg. parquet), reliable open-source table structures (eg. iceberg, delta) and a unified open-source query tool (eg. ibis) makes data lakes more flexible and portable. These elements ensure data can be easily moved, managed and queried across different platforms. It also makes it easier for these data lakes to be spawned in local environments enabling local workflow testing prior to pushing to cloud-based production.
Embedded Databases as viable Serverless Solutions
The client/server architecture for databases has been around for a very long time, and has been proven to be a successful commercial model, which is why they are the norm in large-scale production use cases. However, they aren’t well adapted to serverless use-cases, since they require to be on all the time, incurring server costs, even if they aren’t being actively used. It turns out that new embedded database model solves this problem, so we should sit up and take note. There are a number of very informative blog-posts 14 on embedded-databases that are recommended reading. We also include a one-pager (embedded below) that discusses some of the tools out there that deliver compelling value across relational, graph and vector data-model paradigms.
An embedded database is an in-process database management system that’s tightly integrated with the application layer. The term “in-process” is important because the database compute runs within the same underlying process as the application. A key characteristic of embedded databases is how close the storage layer is to the application layer. Additionally, data that’s larger than memory can be stored and queried on-disk, allowing them to scale to pretty huge amounts of data (TB) with relatively low query latencies and response times.
The evolution of modular data-tooling has been an important driver of the new database models, with Arrow as a de-facto standard for efficiency gains with in-memory and on-disk capabilities that are core features of this new class of embedded database. The embedded architecture is still relatively new, at least for OLAP databases, nevertheless vendors are delivering rich feature-sets as open-source solutions, even as they figure out their monetization strategies.
Being able to dispense with traditional databases in favour of cheaper object-stores, such as S3 is a game-changer. It means you can work with ever-scaling amounts of data, that working with AI-based solutions requires, benefit from the low-cost object-store model and get to keep the query-processing power that embedded-databases bring. You also don’t have to compromise on query latency, with the advent of more performant variants such as S3 Express.
The Ubiquity of DuckDB
Wes McKinney also posited here15 that the ability to add cutting-edge analytic SQL processing to almost any application is a disruptive and transformative change for our industry — in effect, that every DBMS will have the same vectorized execution capabilities that were unique to Snowflake ten years ago.
From Figure 5, sitting alongside the likes of Snowflake on the execution-engine layer of our composable data system is DuckDB, which has become a ubiquitous component of most data-stacks for its versatility. First introduced in 2019, akin to SQLite, it allows you to store your data in a single .duckdb database file, making it easily portable within other projects. It dispenses with the client-server convention — all you need to do is point to where the single DuckDB database file is stored (that could be remotely), or start an in-memory session without even requiring to use a physical database. In fact, here is a great illustration16 of what’s possible with DuckDB.
Alluding to our earlier discussions around the importance of standards, DuckDB has an ability to run SQL queries directly on Python dataframes, enabling it to query Pandas, Polars and Apache Arrow dataframe objects as though they were SQL tables. In the case of the latter, it leverages a zero-copy-mode that dispenses with the data-serialisation overhead of old, often a bottleneck for data-tooling. With DuckDB, you can directly query DBMS systems like MySQL and Postgres, open data files like JSON, CSV, and Parquet files stored in cloud storage systems like Amazon S3, and modern open table formats like Apache Iceberg and Delta Lake. For illustration, below is a basic query running on DuckDB that encapsulates a data pipeline to push parquet files from a public to private bucket and then write an aggregation query to update that private data-source.

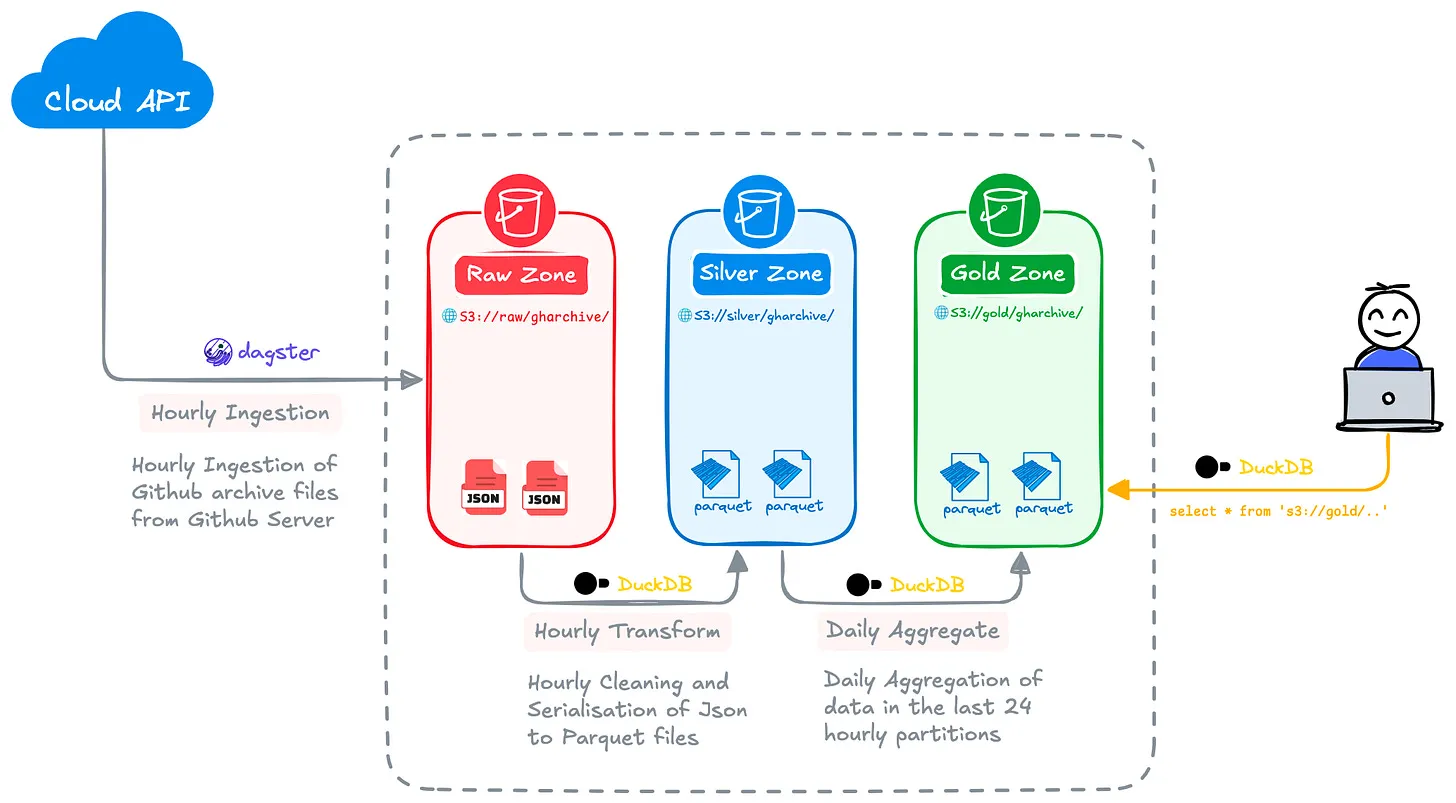
Below are a selection of one-pagers relevant to our discussions derived from a library I maintain around these technologies for my own and my clients’ reference. These are intended as summaries and don’t look to cover a topic thoroughly, but often link off to more detailed resources.
New Generation of Pipeline and Orchestration Tools
The Composable Codex envisaged three layers of a minimum viable data-system — data, execution and UI (expression). The DAGWork’s variant is presented below, where they include an asset layer that is responsible for structuring code into assets that are meaningful to the business and, for producing them, the orchestration layer that triggers their computation.
- Data: the physical representation of data, both inputs and outputs
- Execution: perform data transformations
- Expression: the language to write data transformations
- Asset: an object in persistent storage that captures some understanding of the world (e.g., a dataset, a database table, an ML model, dashboards)
- Orchestration: operational system for the creation of assets

Pipeline solutions like Airflow, Dagster, Hamilton and Kedro, all use a directed-acyclic-graph (DAG) to represent a pipeline, specifying how ‘assets’ (a node within the DAG) relate and depend upon eachother. Imperative systems (like Airflow) require developers to expressly tell the orchestrator ‘what to do’. Declarative ones (like Dagster and Hamilton), declare what can be computed and each function infers its dependencies.
Common to all tools we profile here is the ability to run and test locally, but also then the possibility of running them in-production in the cloud, usually without any need to adjust the code much, if at all, making them efficient to work with. Refer to the ‘New Generation of Pipeline Tools’ tab above, for an embedded one-pager that discusses these tools that are integral to the composable data system in more detail.
Greater Alignment to ML / AI Workloads
Before we wrap up this high-level review of the data-tooling landscape, let’s bridge to our next topic of LLMs.
Companies are increasingly turning to machine learning and AI tools to clean up existing data. A large body of in-situ machine-learning algorithms are classical in nature, involving supervised learning, which involves the labeling of data. These algorithms tend to be performant (in terms of inference cost and latency) and are improved as the underlying data on which they are trained is potentially improved, with the advent of LLMs that can be used to more easily generate more accurate features from underlying data with other LLMs simultaneously used to ‘judge’ the quality of what was generated. Known as Data-centric AI (DCAI), this is an emerging field that studies techniques to improve datasets and considers the improvement of data as a systematic engineering discipline. On the contrary, Model-centric AI19 is about model-selection, training techniques and hyperparameter selection to maximise model performance without altering the data.
The sheer size of data needing to be handled in the context of working with LLMs is demanding a more performant data layer. Per this talk20, Chang She, CEO of LanceDB, contends that the current need to duplicate data depending on the end use-case, in the context of experimentation with AI, is inconvenient and expensive. You have a requirement to hold raw data, vector data, often tensor-based data in a different form again, with each potentially duplicated further with experimentation around adjusting a relevant feature-set.
His solution, LanceDB (also a new-breed embeddable database), is able to have a single data-store and therefore a single source of truth that is able to hold multi-modal raw data and the calculated vectors from that data as well as various forms of indexing that sits above that data, making it potentially seamlessly available to different end use-cases in the requisite formats. This makes it much more amenable to being a composable solution for data in an AI training and exploration context.
We’ll dive into LLMs: Key Emerging Components of the AI Tech Stack, in our next blog-post.
Footnotes
The AI Hierarchy of Needs, Monica Rogati, June 2017.↩︎
2024 Gartner Market Guide to DataOps, DataKitchen Marketing Team, Aug. 2024↩︎
Nine dimensions for assessing data quality: Rewired, The McKinsey Guide to Outcompeting in the Age of Digital and AI, Wiley, June 2023.↩︎
The Road to Composable Data Systems:, Thoughts on the Last 15 Years and the Future, Wes McKinney, September 2023↩︎
The Composable Data Management System Manifesto, Proceedings of the VLDB (very large database) Endowment, Volume 16 No. 10, Pedro Pedreira et al., June 2023↩︎
GPU-powered data science enables much greater interactivity, but affords fewer coffee breaks, Shashank Prasanna & Mark Harris, NVIDIA, Oct. 2018↩︎
A composable data system, with 3 key standards: Open standards over silos, Chapter 1, Open Standards, The Composable Codex, Voltron Data, 2023↩︎
Ibis is a composable UI that can interoperate with multiple execution engines and data storage layers.: Bridging divides: Language interoperability, Chapter 2, Language Interoperability, The Composable Codex, Voltron Data, 2023↩︎
Code flows from the user through the UI, which then passes the IR (intermediate representation) plan to the engine for execution: Bridging divides: Language interoperability, Chapter 2, Language Interoperability, The Composable Codex, Voltron Data, 2023↩︎
Comparison of the three connectivity approaches: From data sprawl to data connectivity, Chapter 3, Data Connectivity, The Composable Codex, Voltron Data, 2023↩︎
The advent of the Open Data Lake:, Julien Le Dem, Nov. 2024↩︎
The advent of the Open Data Lake:, Julien Le Dem, Nov. 2024↩︎
Lakehouse: A New Generation of Open Platforms that Unify Data Warehousing and Advanced Analytics, Michael Armbrust et al., Jan. 2021.↩︎
The Data Quarry: Series on Embedded Databases, Prashant Rao, 2023↩︎
The Road to Composable Data Systems:,Thoughts on the Last 15 Years and the Future, Wes McKinney, September 2023↩︎
DuckDB Doesn’t Need Data To Be a Database, Nikolas Gobel, May 2024↩︎
Sample DuckDB-centric data pipeline enabled by DuckDB from DuckDB Beyond the Hype, Alireza Sadeghi, Sept. 2024.↩︎
DAGWork’s 5-layer modular data-stack from Hamilton & Kedro for modular data pipelines, DAGWorks, Mar. 2024.↩︎
Data-Centric AI vs. Model-Centric AI MIT Lecture series, 2024↩︎
Foundations for a Multi-Modal Lakehouse for AI, Data Council Technical Talk, April 2024↩︎
Citation
@misc{mccoole2025,
author = {{Colum McCoole}},
title = {4. {DataOps:} {Emerging} Powerful Modular Tooling},
date = {2025-02-28},
url = {https://analect.com/posts/ai-strategy-series/4-dataops-modular-tooling/},
langid = {en-GB}
}