5. LLMs: Key Emerging Components of the AI Tech Stack
Convinced of the value LLMs can bring, the challenge becomes how can we securely and reliably get LLMs to perform complex tasks with real-world data.
LLMs have become progressively more capable and exponentially cheaper over the past two years. While they need careful curation when deployed as part of an overall business solution, LLMs have the potential to bring significant value to a business.
Unlike traditional ML models, which operate on structured data, LLMs handle the vast and often messy world of text and code. This introduces a new layer of complexity, which demands special techniques for data ingestion, pre-processing, and training.
LLMOps is about production monitoring and continual improvement, linked by evaluation. The better your evals, the faster you can iterate on experiments, and thus the faster you can converge on the best version of your system.
- #4. DataOps Strategy: Embedding Data Everywhere
- #5. LLMs: Key Emerging Components of the AI Tech Stack (this one)
LLM State of Play
If you skip this section, the only thing I would urge you to take away is that LLMs are getting more capable by the day and the cost of using them has plummeted. There’s also a mix of as-good-as-best-in-class opensource models now available, with variants that are viable to self-host, bringing with it more choice for users that may not wish to utilise API endpoints of the big foundation-model vendors. This, together with some other use-cases I hope to demonstrate in here, should convince those on the fence to embrace this innovation for their business.
Given the pace of innovation in LLMs, it’s a somewhat moveable topic, so it’s perhaps useful to take a snapshot of where we currently stand in Q1 2025. In this field, I defer to better experts than myself and Simon Willison’s uncanny ability to offer precient observations1 makes him a go-to source. In a recent review2, he made some of following observations:
- while 2023 was a ‘slow’ year for LLMs, with OpenAI maintaining dominance for most of that year with GPT-4, 2024 saw the pace of innovation spike, with as many as 18 labs3 producing GPT-4 equivalent models.
- 2024 was also the year of multi-modal LLMs, taking LLMs beyond text and gaining capabilities in processing images, audio and video.
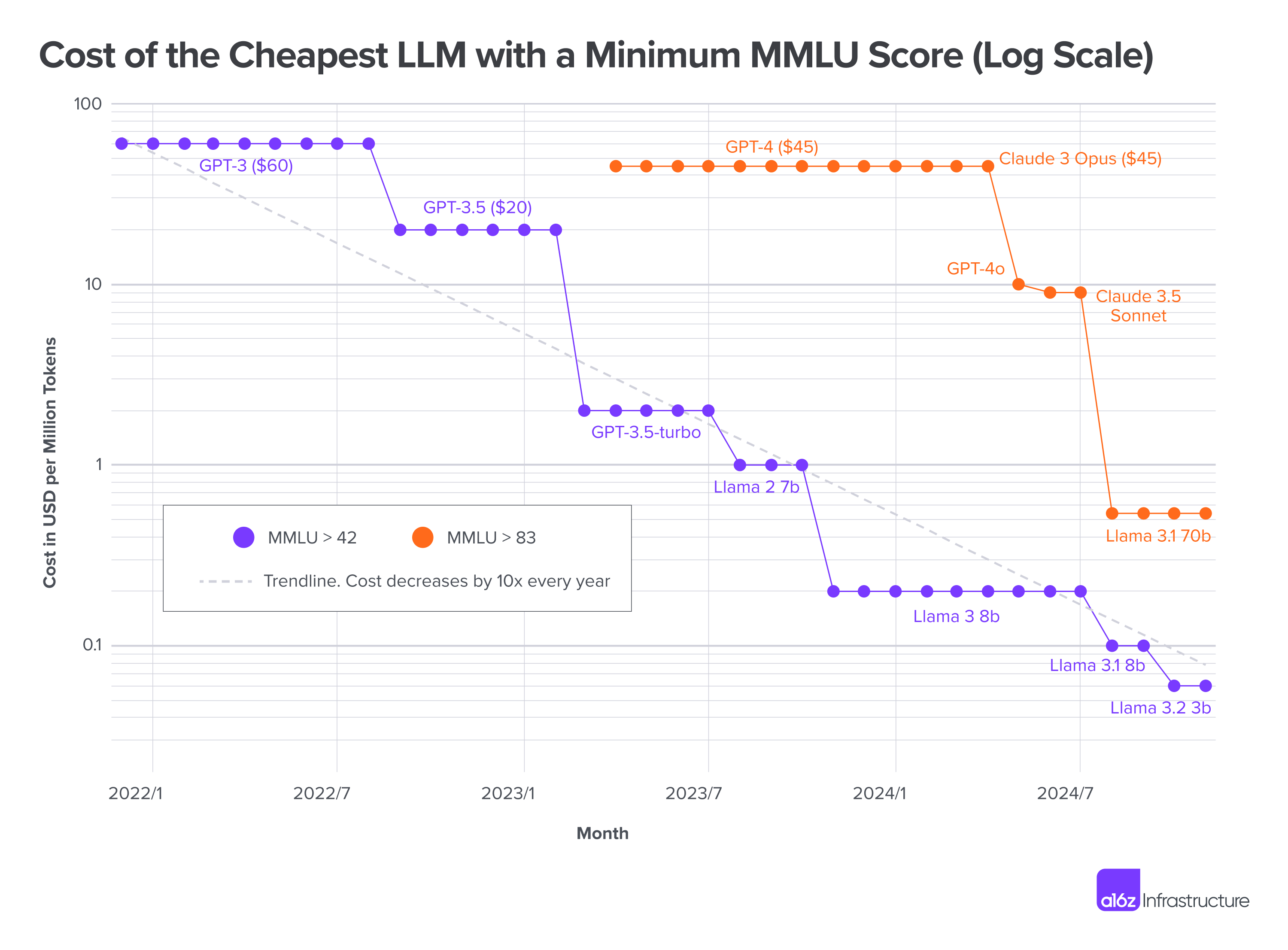
- pricing for usage of the most capable models has continued to decline precipitously (Figure 1) making the economics of using this technology all the while more compelling. Willison describes being able to label 68k photos with descriptions for a sum total of $1.68, leveraging Gemini 1.5 Flash 8B.
- he also points to the step-change in the sophistication of models that is now possible to run on local hardware, as even more capability is gettting packed into ever-smaller variants. He actively records these milestones as he experiments, offering a valuable time-line of progress, such as these, from November through January.
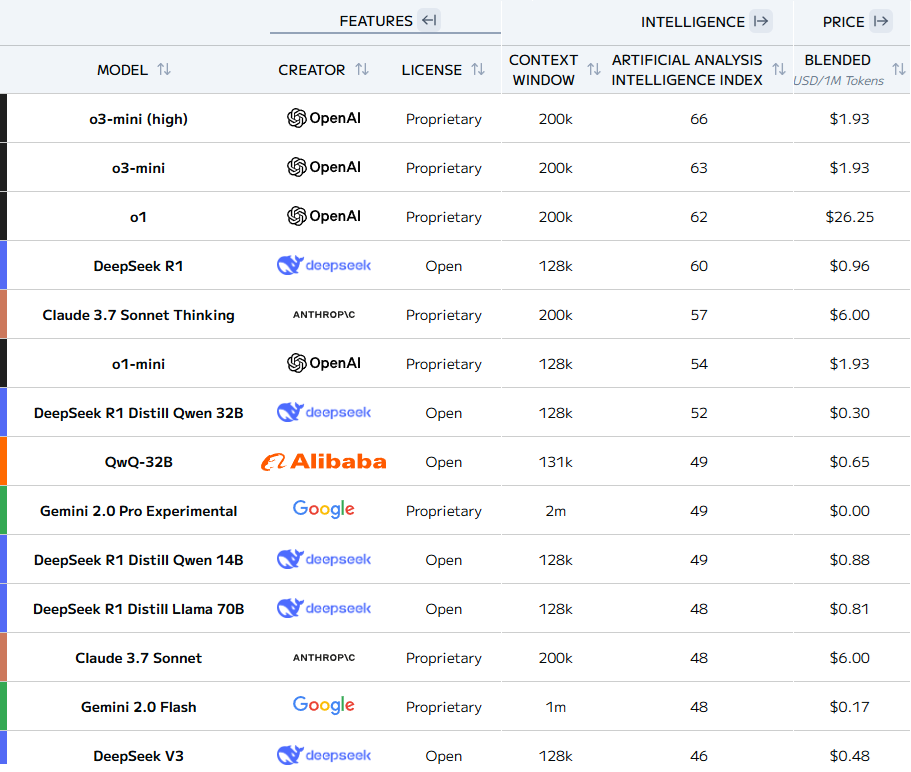
- per model ranking in Figure 2, the presence of top-ranked opensource models is predominantly down to the efforts of labs from China, including DeepSeek and Alibaba (Qwen).
- January 2025 marked the arrival of DeepSeek V3 and R1 models, which you may recall rattled people’s assumptions around the possibility of being able to train these cutting-edge models for much less in compute cost than was previously assumed. It turns out that the low training cost posted at the time was taken a little out of context.
- Most compellingly, DeepSeek have been the first to properly opensource their methods (not just weights), which is a step-change.
- A note from Anthropic’s CEO6, in which he argues for even stronger efforts to limit advanced chips for China, he posits that the interest in their reasoning R1 model was elevated, since they were the first to expose the Chain-of-Thought reasoning to users. You’ll recall, OpenAI’s o1 only gives you the final answer.
- In that same note, Amodei argues “DeepSeek-V3 is not a unique breakthrough or something that fundamentally changes the economics of LLM’s; it’s an expected point on an ongoing cost reduction curve. What’s different this time is that the company that was first to demonstrate the expected cost reductions was Chinese.”. Take from that what you will.
- The top-ranked models (Figure 2) are predominantly reasoning (inference-time compute) ones — OpenAI o1 and o3, DeepSeek R1, Qwen QwQ, Claude 3.7 Thinking and Gemini 2.0 Thinking are all examples of this pattern in action — or so-called MoE (mixture of experts)7, with Deepseek-V3 using as many as 256 different experts, per their paper8. Technical readers may find this discussion9.
- Willison also observes that these models are getting much better at handling PDFs and he offers well-documented approaches to leveraging this10. For instance, Gemini and Claude can both accept PDFs directly. For other models (including OpenAI) you need to break them up into images first—a PNG per page works well. These capabilities and reduced cost will only accelerate the sophistication of RAG (retrieval-augmented-generation) systems, a foundational capability for any business looking to use these technologies, as we’ll elaborate on lower down.
LLMs as a Developer Tool
The ability to leverage LLMs, as a developer tool, has dramatically changed the time-frame (and economics) of developing a model that can be iterated upon to solve a business problem. Convinced of the value they can bring, the challenge becomes how can we securely and reliably get LLMs to perform complex tasks with real-world data.
For most LLM applications out there, your development steps will involve the selection of a foundation model, which you further have to optimize by using prompt engineering, fine-tuning, or RAG11. The operational aspect of these three steps is the most critical to understand, something we’ll touch on in the LLMOps section below. For those keen to move beyond the abstract, I can whole-heartedly recommend the LLM Engineer’s Handbook12, which leads the reader through an end-to-end project implementation, which I personally think is the best way of gaining a clear understanding of how these technologies work and, more importantly, offers a spring-board for implementing a solution particular to your own business.
Understand Different AI User-types
How you leverage LLMs as a business and the requisite sophistication of your LLMOps capability depends on the type of user you identify as. A helpful blog from AWS (linked below the diagram) depicts three main user-types along a continuum, with most users, as of today, probably identifying as ‘consumers’ — tapping into API end-points to feed an LLM some task. The ‘providers’ are the ones building models from scratch, where obviously much fewer organisations have such capabilities. In the middle are the ‘fine-tuners’, those that recognise the power of LLMs and that are prepared to build a level of expertise to be able to refine models for needs specific to their business use-cases.
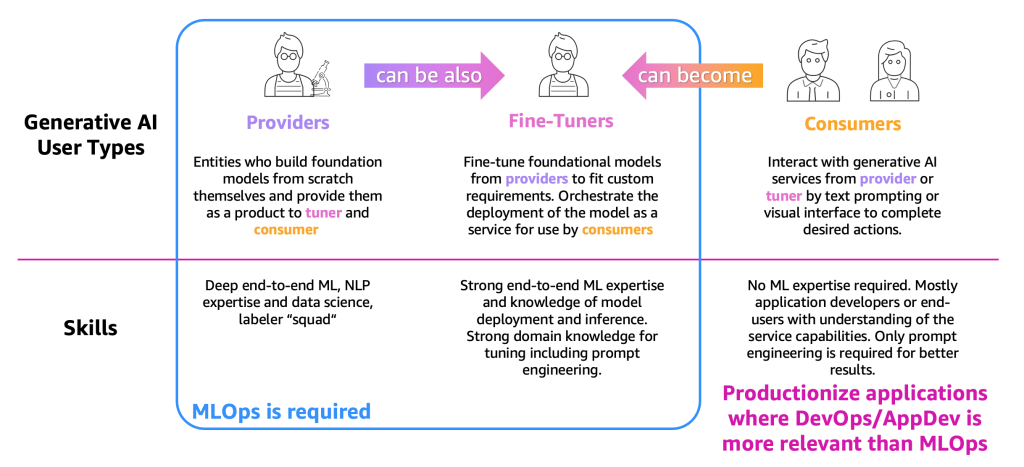
- Providers - train models that are general-purpose. Each trained model needs to be benchmarked against many tasks not only to assess its performances but also to compare it with other existing models, to identify areas that needs improvement. Providers might become fine-tuners to support use cases based on a specific vertical (such as the financial sector).
- Fine-tuners - want to solve specific tasks (e.g. sentiment classification, summarization, question answering) as well as pre-trained models for adopting domain specific tasks. They need evaluation metrics generated by model providers to select the right pre-trained model as a starting point. they must curate and create their private datasets since publicly available datasets, even those designed for a specific task, may not adequately capture the nuances required for their particular use case.
- Consumers - consume general purpose or fine-tuned models in production, aiming to enhance their applications or services through the adoption of LLMs. robust monitoring and evaluation framework, model consumers can proactively identify and address regression in LLMs. Consumers might become fine-tuners to achieve more accurate results.
As a proving ground for developing AI use-cases, the AWS ecosystem is no bad starting point, since they do the heavy-lifting around security on your behalf, allowing you to focus on evolving a solution that can add value. Their Bedrock platform offers a single API to various different LLM foundation-model providers and is best suited to the ‘consumers’ identified above. It offers an out-of-the-box solution that allows you to quickly deploy an API endpoint powered by one of the available foundation models.
Alternatively, their SageMaker is a multi-functional platform enabling you to customize your ML logic fully and is aimed at the ‘fine-tuners’, if not the ‘providers’. This incidentally is the system leveraged by the end-to-end project contained in the LLM Engineer’s Handbook, linked to earlier, for its greater versatility.
Importance of the RAG Pattern
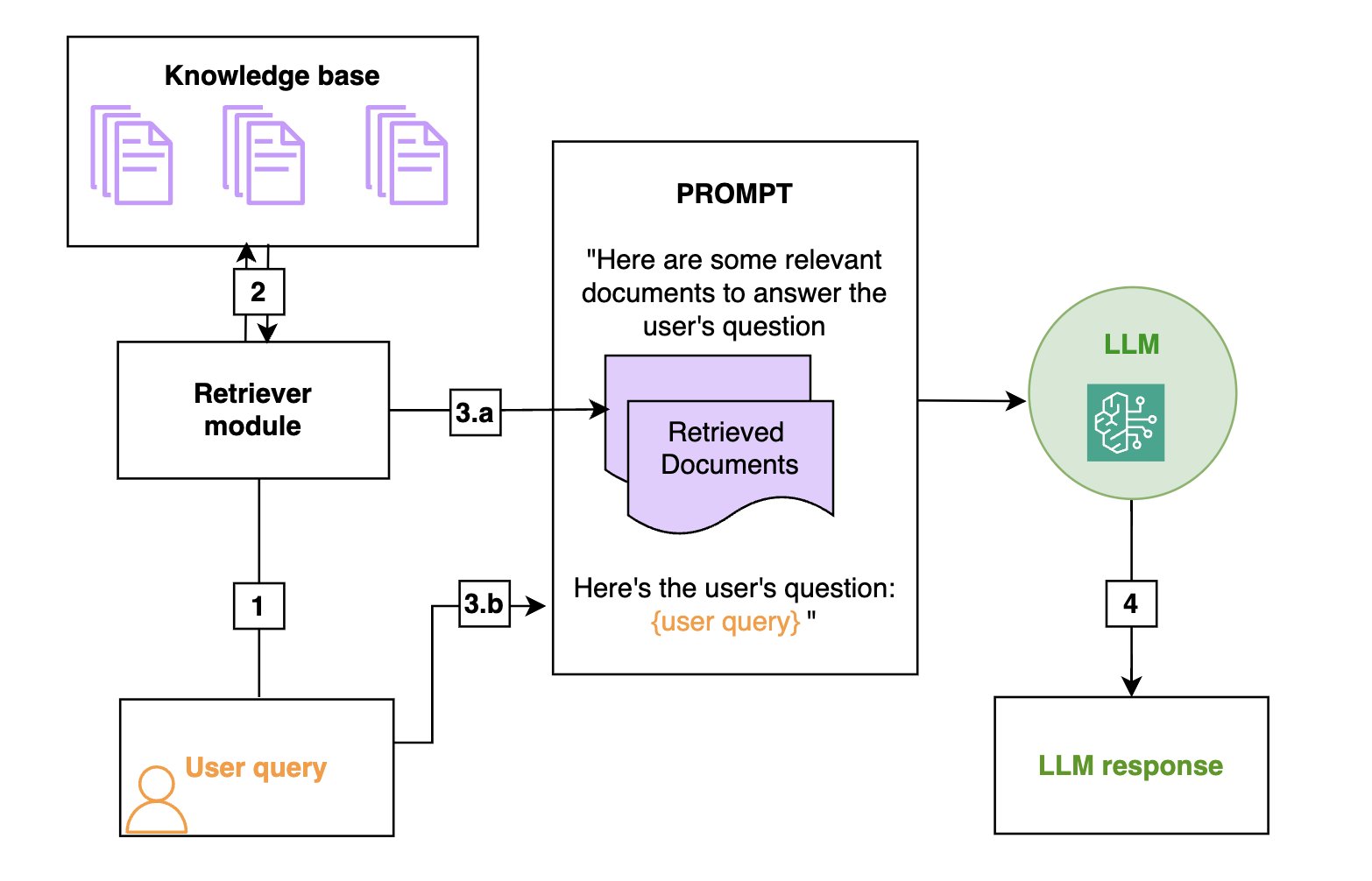
RAG is an efficient way to provide an FM (foundation model) with additional knowledge by using external data sources and is depicted in the diagram on the left:
- Retrieval: Based on a user’s question (1), relevant information is retrieved from a knowledge base (2).
- Augmentation: The retrieved information is added to the FM prompt (3.a) to augment its knowledge, along with the user query (3.b).
- Generation: The FM generates an answer (4) by using the information provided in the prompt.
From left to right (on left) are the retrieval, the augmentation, and the generation steps. In practice, the knowledge base is often a vector store, allowing for hybrid of key-word and semantic search.
Some Common RAG Use-cases:
- Employee training and resources – In this use case, chatbots can use employee training manuals, HR resources, and IT service documents to help employees onboard faster or find the information they need to troubleshoot internal issues.
- Industrial maintenance – Maintenance manuals for complex machines can have several hundred pages. Building a RAG solution around these manuals helps maintenance technicians find relevant information faster. Note that maintenance manuals often have images and schemas, which could put them in a multimodal bucket.
- Product information search – Field specialists need to identify relevant products for a given use case, or conversely find the right technical information about a given product.
- Retrieving and summarizing financial news – Analysts need the most up-to-date information on markets and the economy and rely on large databases of news or commentary articles. A RAG solution is a way to efficiently retrieve and summarize the relevant information on a given topic.
With experience, an organisation’s sophistication in using these technologies will grow. As articulated in this blog15:
A more scalable option is to have a centralized team build standard generative AI solutions codified into blueprints or constructs and allow teams to deploy and use them. This team can provide a platform that abstracts away these constructs with a user-friendly and integrated API and provide additional services such as LLMOps, data management, FinOps, and more. Establishing blueprints and constructs for generative AI runtimes, APIs, prompts, and orchestration such as LangChain, LiteLLM, and so on will simplify adoption of generative AI and increase overall safe usage. Offering standard APIs with access controls, consistent AI, and data and cost management makes usage straightforward, cost-efficient, and secure.
Moving Beyond Chatbots and RAG Implementations
Anyone who has been following the development of LLMs over the past few years is probably suffering from chatbot or rag-system fatigue, since these are often presented as the pinacle of what these models are capable of, which of course is not the case. That’s why a use-case from Outerbounds16 (maintainers of Metaflow) presented last year caught my eye, since it offers a more realistic glimpse of where we’re heading with these capabilities. We’ve tried to encapsulate its key message in the box below. Essentially it takes a banal furniture retailer website, for which little has changed in recent decades, and demonstrates how overlaying such a site with AI capabilities can be completely transformative. The narrative is probably easier to follow using the full-sized slides17 and listening to the presentation. The point here is to illustrate the transformative effect that embeddeding machine-learning can have on a business.
Outerbounds (Metaflow) Use-case — New Web Technologies leveraging AI
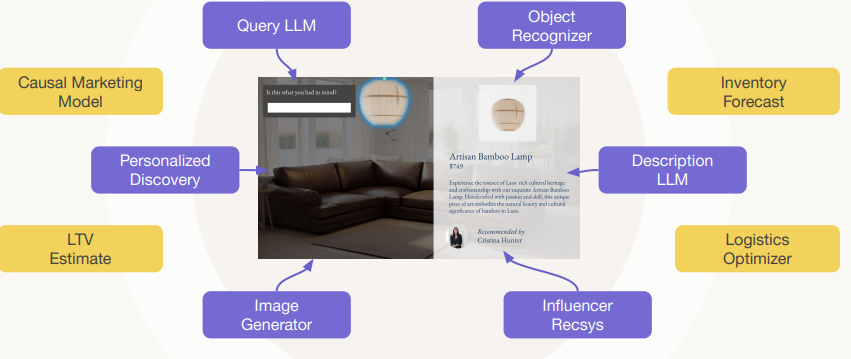
To illustrate the changing sophistication of websites, a furniture retailer site is used. For the past 30 years, the same basic website design entails giving users an ability to filter available stock by price, type etc. with a query to the backend and the front-end refreshing to show the available products. The only real change in this model up until recently has been slicker photos of the products.
However, with the arrival of LLMs, it’s now possible to allow users to place products into a picture of their own room and to interactively swap out products using natural language. Certain objects added within an image can be queried based on where you click within that image. LLMs can be used to improve product description summaries and a whole host of other things (blue squares on right). Various other modelling opportunities with collected data present themselves (yellow squares on right), taking the degree of sophistication around customer interaction to new heights.
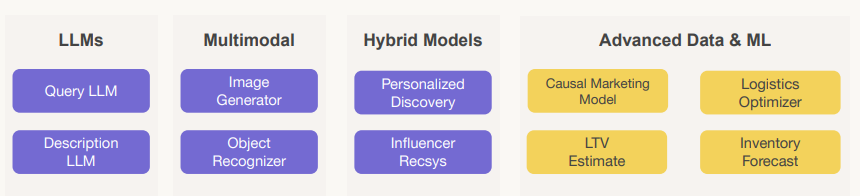
While all the focus these days seems to be on LLMs, a much broader set of models will become important in the coming years. This includes:
- Multi-modal - where text, audio, images and potentially video are handled by a single model. Use-cases, based on our simple furniture retailer, might include an image-generator (show me a leather sofa) and object-recognizer (what is this lamp that has been placed in the image).
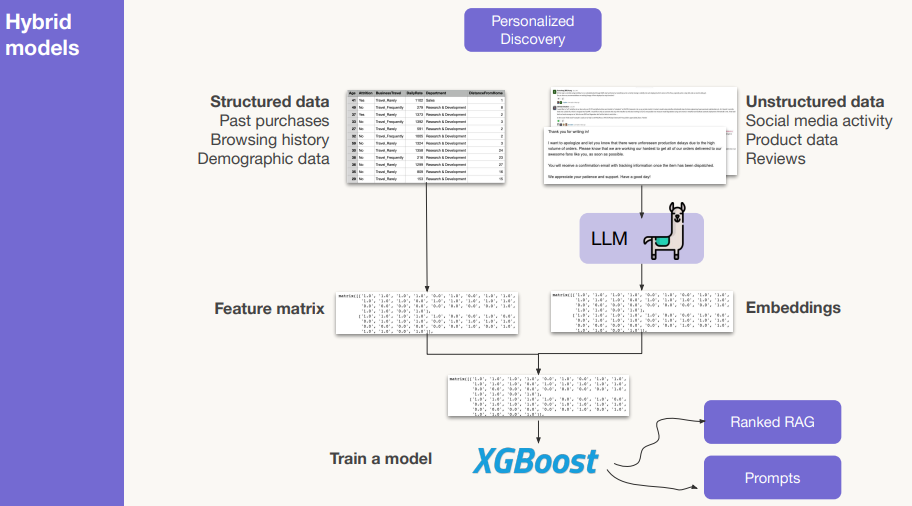
- Hybrid Models - this is where pre-existing machine-learning models can be further enhanced with richer data-sets aided by LLMs that can help surface that data from unstructured sources (see Figure 6).
- Advanced Data & ML
- causal marketing model - a sub-domain of models dedicated to better understanding the cause and effect of interactions with end-consumers intended to prompt some action. Should we offer them a discount? Are they more likely to desire a leather sofa?
- LTV estimate - life-time value calculation is the predicted revenue generated by a customer over the entire relationship with a company. This will be an important factor in deciding the level of customer acquisiton cost you might be able to afford. LTV = ARPU x Customer Lifetime or LTV = ARPU/User Churn
- Logistics optimzer - which products are most profitable to sell to consumers and easily available/deliverable.
- Inventory forecasting - how much inventory of each product should we ideally be holding?
LLM Codegen Workflow
Much of our discussion of LLMs so far has been very much at the macro level — how can a LLM be deployed as part of a RAG system or used to underpin image generators or object recognizers on a modern website. But of course, LLMs, particularly those that are orientated towards code-generation, have become invaluable at the micro-level for developers too. As an illustration of this, Simon Willison’s blog that we linked to earlier, is teeming with examples of how he levers LLMs cleverly to bring greater levels of productivity to his work. His own llm CLI tool is being constantly enhanced for better integration into new capabilities being enabled by large language models. Another seasoned developer and blogger, Harper Reed, has also penned a valuable piece19 which illustrates his usage of LLMs to structure a software solution through a series of question prompts, which he then step-by-step converts into code, also leveraging LLMs. In addition to ‘greenfield’ coding, he adapts this approach to work with legacy code-bases too. There have been plenty of doom-and-gloom narratives around the damaging effect of Co-pilot on nascent programmers, but like any tool, LLMs, when wielded sensibly, can be massively productivity-enhancing.
LLMOps is more than an Extension of MLOps
A single prompt fed into an LLM might produce varying responses over time. This can lead to inconsistencies in applications powered by LLMs. LLMOps implements strategies to manage output consistency. Unlike traditional ML models, which operate on structured data, LLMs handle the vast and often messy world of text and code. This introduces a new layer of complexity, which demands special techniques for data ingestion, pre-processing, and training.
While MLOps addresses the principles and practices of managing various ML models, LLMOps focuses on the distinct aspects of LLMs, including their large size, highly complex training requirements, prompt management, and non-deterministic nature of generating answers.20
I’m not about to go down a rabbit-hole and teach you about LLMOps, when others have done that more eloquently (follow the linked footnote above). What I will do, however, is point you towards a group of practitioners in this field (Applied LLMs) that have assembled an invaluable resource mid 2024 that runs through their experiences and ‘lessons-learned’ from a year shipping LLM applications21, with a video version here22. They split their learnings under Tactical, Operational and Strategy headings. We’ve tried to summarise the tactical part in the grey box within the embedded PDF below. I would encourage you to read the full note, linked above.
Takeaways from the piece I found most compelling include:
- The model isn’t the product, the system around it is - For teams that aren’t building models, the rapid pace of innovation is a boon as they migrate from one SOTA (state-of-the-art) model to the next, chasing gains in context size, reasoning capability, and price-to-value to build better and better products.
- calibrate risk tolerance based on the use-case - for less critical applications, such as a recommender system, or internal-facing applications like content classification or summarization, excessively strict requirements only slow progress without adding much value.
- Focus on model evaluation - LLMOps is about production monitoring and continual improvement, linked by evaluation. The better your evals, the faster you can iterate on experiments, and thus the faster you can converge on the best version of your system.
- Empower everyone to use new AI technology - while it may seem expensive to have a team spend a few days hacking on speculative projects, the outcomes may surprise you.
Risks with Using LLMs
This is a broad topic, best tackled elsewhere in-depth, but as a helpful starting point, I would point you toward this blog23, where the authors, viewing through a generative AI lens, acknowledge the need to address the intricate challenges and opportunities arising from Generative AI’s innovative nature, which would include the following aspects:
- Complexity can be unpredictable due to the ability of large language models (LLMs) to generate new content
- Potential intellectual property infringement is a concern due to the lack of transparency in the model training data
- Low accuracy in generative AI can create incorrect or controversial content
- Resource utilization requires a specific operating model to meet the substantial computational resources required for training and prompt and token sizes
- Continuous learning necessitates additional data annotation and curation strategies
- Compliance is also a rapidly evolving area, where data governance becomes more nuanced and complex, and poses challenges
- Integration with legacy systems requires careful considerations of compatibility, data flow between systems, and potential performance impacts.
Any generative AI lens therefore needs to combine the following elements, each with varying levels of prescription and enforcement, to address these challenges and provide the basis for responsible AI usage:
- Policy – The system of principles to guide decisions
- Guardrails – The rules that create boundaries to keep you within the policy
- Mechanisms – The process and tools
LLM Evals and Monitoring
Among the practitioners alluded to earlier, Hamel Husain blogs24 extensively on LLMs, often with very pertinent content based on his direct consulting experience in implementing AI systems with clients. His big insight (per Figure 7) is that improvement requires process — you need to be evaluating your LLMs constantly in order to iterate for their improvement. Evaluation of a customized LLM against the base LLM (or other models) is necessary to make sure the customization process has improved the model’s performance on your specific task or dataset.
He’s not a big fan of off-the-shelf model evaluation tools. Rather, there can be lots of domain-specific data that needs capturing, so it can often make sense to customise a data-reviewing tool using a simple front-end like Gradio, Streamlit or Shiny. Such an app can also encompass labelling, allowing for capturing human review. A central message is to remove any friction in the process of being able to look25 at your data produced by your LLM app.
LLM-as-a-judge can be helpful as a bolt-on capability to a functioning eval system, but it is really important that it is aligned to a human. Use experts to label LLM-as-a-judge output until this judge-human alignment is sufficiently good. The important thing is not to revert to using this approach too early before exhausting the prompt-engineering and fine-tuning steps. He’s also adamant that you need to design metrics that are specific to your business, along with tests to evaluate your AI’s performance. The data you get from these tests should also be reviewed regularly to make sure you’re on track. There’s a presentation26 on this approach worth watching.
Mental model for improving AI systems
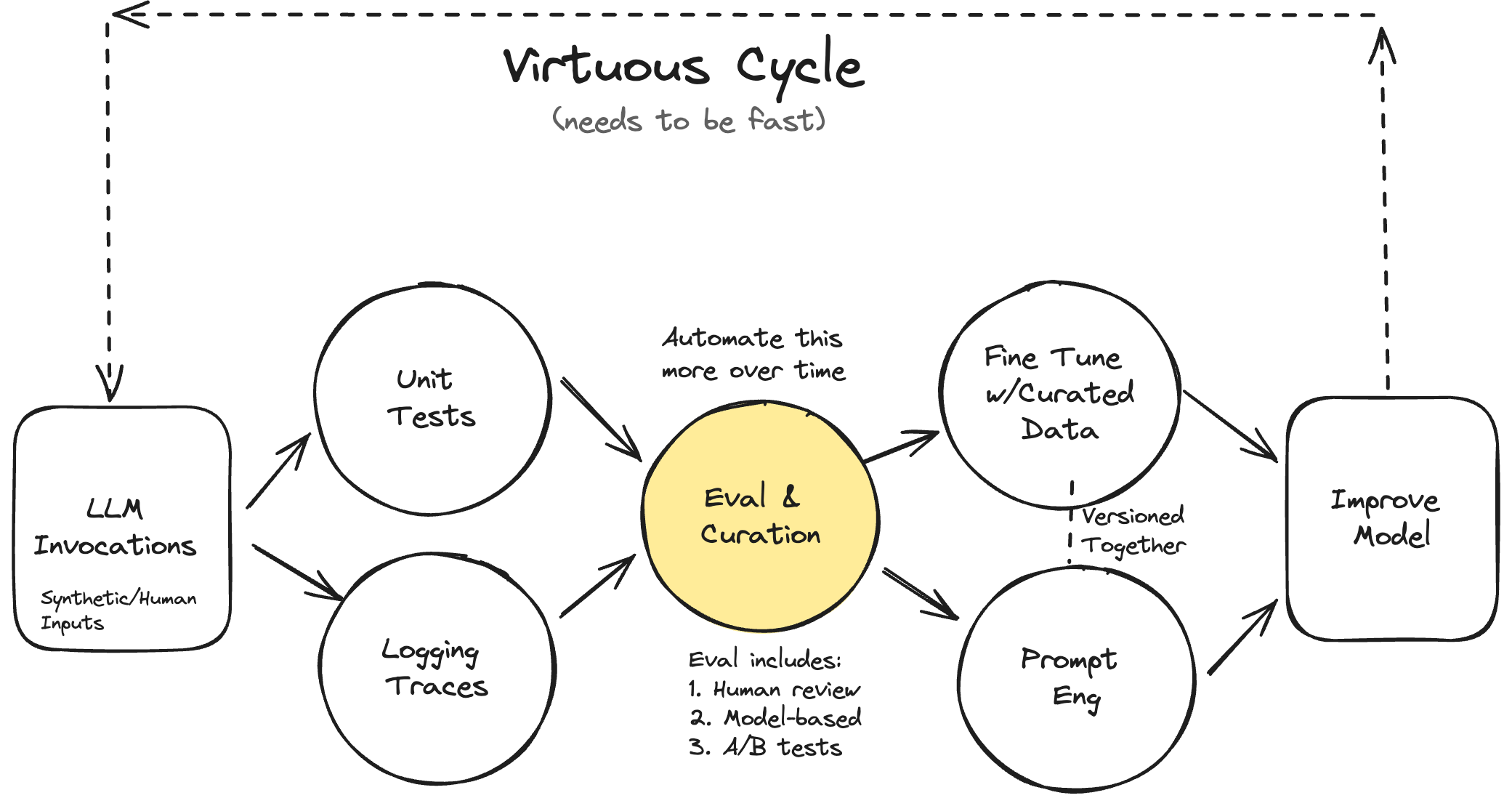
The key insight is that you need both quantitative and qualitative feedback loops that are FAST. You start with LLM invocations (both synthetic and human-generated), then simultaneously:
- Run unit tests to catch regressions and verify expected behaviors. People tend to skip this stuff, however it is the foundation for good evaluation systems. You can potentially use LLMs to synthetically bootstrap test-cases.
- Collect detailed logging traces to understand model behavior. Log your traces to a database of some sort and spend time examining them.
These feed into evaluation and curation (which needs to be increasingly automated over time). The eval process combines:
- Human review
- Model-based evaluation
- A/B testing
The results then inform two parallel streams:
- Prompt engineering improvements - with a minimal evaluation system, you want to begin to iterate on your AI with prompt-engineering. Determine if your test-coverage is good. Are you logging your traces correctly?
- Fine-tuning with carefully curated data - by having a system to capture human evaluation (labelling good and bad cases), this curated data has the potential to be leveraged for fine-tuning a model, driving further improvement.
A useful case-study from the wild on LLM usage28 at Clearwater Analytics and their rigorous LLM evaluation process is available from this blog29. This is evidence of the lengths to which companies, utilising LLMs, will go to ensure that their solutions are particularly robust. We’ve captured the essence of the Clearwater evaluation process in the box below, but we would point you back to the linked blog for more detail. We also have an embedded one-pager lower down, summarising a series of really thoughtful pieces put out by their engineering team. For those looking for a larger-scale evaluation framework that already fully-formed, we would urge your to study this Sagemaker-based30 approach.
Clearwater’s Evaluation Framework for LLMs:
- Attribute Selection: Based on the specific use case, we select a set of attributes and their scoring criteria. These attributes are chosen to best assess the model’s performance in the given context.
- System Prompt Creation: The selected attributes are incorporated into the system prompt, creating a comprehensive instruction set for the AI judges.
- Question Set Preparation: We retrieve a set of curated questions relevant to the use case. Each question comes with a reference answer and contextual information.
- LLM Response Generation: The LLM being evaluated generates responses to these questions.
- User Prompt Construction: We combine the question, reference answer, context, and the LLM’s response into a user prompt.
- Multi-Judge Evaluation: Both the system and user prompts are sent to each AI judge in the panel. This ensures a diverse range of evaluations.
- Result Aggregation and Analysis: The judges’ evaluations are collected, aggregated, and analyzed to form a comprehensive assessment of the LLM’s performance.
![]()
Better Flow Controls for LLM Apps
We’ve covered alot of ground here, so we’ll close-out with a final nod towards some novel opensource tooling designed to aid the development process of LLM Apps, especially ones that expect to leverage calling out to agentic systems. Those with greatest experience in developing LLMs articulate that common friction points with GenAI applications can include logically modeling application flow, debugging and recreating error cases, and curating data for testing/evaluation. The developers of Burr say these problems all got easier to reason about when they modeled applications as state machines composed of actions designed for introspection. An application will hold state and make decisions off of that state. You can therefore capture your application as a state-machine, modifying the state as you go. The nice thing about this tooling is that it’s light-weight, it doesn’t seek to obfuscate function calling (as some other agentic frameworks do) and it has nice byproduct properties allowing for data-gathering for evaluation. We’ve tried to capture the essence of the solution in the one-pager embedded below.
That concludes our intial AI Strategy series. We’ve probably just scratched the surface on various topics, but hopefully we’ve sketched for you an outline for an approach to get started with leveraging AI for your business. We hope to follow-up with another series that gets more technical in nature and that builds upon this foundational perspective we’ve shared.
Footnotes
Simon Willison’s content tagged with ‘llm’↩︎
What’s new in the world of LLMs, for NICAR 2025, National Institute for Computer-Assisted Reporting, 8 March 2025↩︎
18 labs put out a GPT-4 equivalent model in 2024: Google, OpenAI, Alibaba (Qwen), Anthropic, Meta, Reka AI, O1 AI, Amazon, Cohere, DeepSeek, Nvidia, Mistral, NexusFlow, Zhipu AI, xAI, AI21 Labs, Princeton & Tencent (source: Simon Willison)↩︎
LLM inference cost is going down fast, from: Welcome to LLMflation, Guido Appenzeller, a16z, Nov. 2024↩︎
LLM Leaderboard from: artificialanalysis.ai, Comparison of GPT-4o, Llama 3, Mistral, Gemini and over 30 models↩︎
On DeepSeek and Export Controls, Dario Amodei, January 2025↩︎
Mixture of experts (MoE) basics: The MoE architecture uses different subsets of its parameters to process different inputs. Each MoE layer contains a group of neural networks, or experts, preceded by a gating module that learns to choose which one(s) to use based on the input. In this way, different experts learn to specialize in different types of examples. Because not all parameters are used to produce any given output, the network uses less energy and runs faster than models of similar size that use all parameters to process every input.↩︎
DeepSeek-V3 Technical Report, DeepSeek-AI, Dec. 26, 2024↩︎
DeepSeek, Reasoning Models, and the Future of LLMs, a16z partners Guido Appenzeller and Marco Mascorro, discussing reasoning models, 5 March 2025↩︎
Structured data extraction using LLM, Simon Willison, Nicar25 Scraping Workshop, March 2025↩︎
Retrieval-augmented generation (RAG) is fundamental in most generative AI applications. RAG’s core responsibility is to inject custom data into the large language model (LLM) to perform a given action (e.g., summarize, reformulate, and extract the injected data). You often want to use the LLM on data it wasn’t trained on (e.g., private or new data). As fine-tuning an LLM is a highly costly operation, RAG is a compelling strategy that bypasses the need for constant fine-tuning to access that new data.↩︎
Chapter 11 - MLOps and LLMOps, LLM Engineer’s Handbook, Paul Iusztin & Maxime Labonne, Packt Publishing, Oct. 2024↩︎
Operationalization journey per generative AI user type: from FMOps/LLMOps: Operationalize generative AI and differences with MLOps, Sokratis Kartakis and Heiko Hotz, AWS, Sept. 2023.↩︎
From RAG to fabric: Lessons learned from building real-world RAGs at GenAIIC – Part 1, AWS Machine Learning Blog, Oct. 2024↩︎
Achieve operational excellence with well-architected generative AI solutions using Amazon Bedrock, AWS Machine Learning Blog, Oct. 2024↩︎
Beyond MLOps: Building AI systems with Metaflow, Ville Tuulos of Outerbounds presenting at Data Council, April 2024.↩︎
Building AI Systems with Metaflow slide-deck, Ville Tuulos, Outerbounds, April 2024↩︎
An ML/AI-driven company of 2026 from: Building AI Systems with Metaflow slide-deck, Ville Tuulos, Outerbounds, April 2024.↩︎
My LLM codegen workflow atm, by Harper Reed, 16 Feb. 2025↩︎
Chapter 11 - MLOps and LLMOps, LLM Engineer’s Handbook, Paul Iusztin & Maxime Labonne, Packt Publishing, Oct. 2024↩︎
What We’ve Learned From A Year of Building with LLMs, June 2024↩︎
Lessons From A Year Building With LLMs, AI Engineer conference, July 2024↩︎
Achieve operational excellence with well-architected generative AI solutions using Amazon Bedrock, Akarsha Sehwag, Zorina Alliata, Malcolm Orr, and Tanvi Singhal, AWS, Oct. 2024.↩︎
Hamel Husain blog on matters pertaining to LLMs at https://hamel.dev/↩︎
Looking at Data: Your Secret Weapon, Hamel Husain, Jan. 2025↩︎
How to Construct Domain Specific LLM Evaluation Systems: Hamel Husain and Emil Sedgh, Rechat development of Lucy, an AI personal assistant designed to support real estate agents.↩︎
How To Systematically Improve The AI from: Your AI Product Needs Evals, How to construct domain-specific LLM evaluation systems, Hamel Husain, March 2024.↩︎
How Clearwater Analytics is revolutionizing investment management with generative AI and Amazon SageMaker JumpStart AWS Machine Learning Blog, Dec. 2024↩︎
A Cutting-Edge Framework for Evaluating LLM Output, Clearwater Analytics Engineering, Aug. 2024↩︎
Operationalize LLM Evaluation at Scale using Amazon SageMaker Clarify and MLOps services, Sokratis Kartakis, Jagdeep Singh Soni, and Riccardo Gatti, AWS, Nov. 2023.↩︎
Citation
@misc{mccoole2025,
author = {{Colum McCoole}},
title = {5. {LLMs:} {Key} {Emerging} {Components} of the {AI} {Tech}
{Stack}},
date = {2025-03-07},
url = {https://analect.com/posts/ai-strategy-series/5-llm-apps-llmops/},
langid = {en-GB}
}