3. Platform Engineering for Evolving AI / ML Solutions
The process of extracting business value from AI is complex which is why you want systems in place, namely platforms, that allow for a combination of experimentation and productionisation and for this to work iteratively.
To do machine-learning well requires rigour. Models trained on data are only as good as the data they are trained on and that data is changing, rendering older models useless. That’s where platforms come in. They contain the foundational blocks on which the process of MLOps gets performed. Clearly platform usage extends beyond machine-learning, but let’s view them in this more confined context here.
Platforms work well when they help automate processes and when the feedback loop for those developing solutions is fast, requiring the underlying compute infrastructure to be fast. This is what is commonly referred to as the fly-wheel effect, enabling value-creation.
- #1. Framing an AI Strategy: Where Do You Start?
- #2. AI is Here, But its Business-Applicability may not be Obvious
- #3. Platform Engineering for Evolving AI / ML Solutions (this one)
Envisioning a Tech Stack
Up to this point, we haven’t talked much about technology, for good reason — there are important structural and cultural elements that needed to be in place in an organisation so that the technology lands on fertile ground. Working with technology in pursuit of, let’s say, a machine-learning driven business, is complex and involves knitting together many systems and tools and then potentially running them in clusters in the cloud, which have a host of complexities themselves. But as we have laid-out in the first blog of this series, it’s possible to do things in stages and, in fact, you can get a long way with some basic components in place.
Platform-engineering is about simplifying that journey for users in general — not just developers or data-scientist, per se. For machine learning to pervade the culture of an organisation, everyone in an organisation should be able to discover and experiment with these solutions. Having a common platform to do this can be transformative, since it reduces the barriers to entry for those less tech-savvy, but nonetheless motivated to learn more technically in the field of machine-learning and AI more generally.
In my own learning journey, I’ve experimented with lots of technologies and built-out my own blueprint platform (Figure 1), including leveraging Backstage1, in order to reap the benefits that I’m articulating here. More on that later.
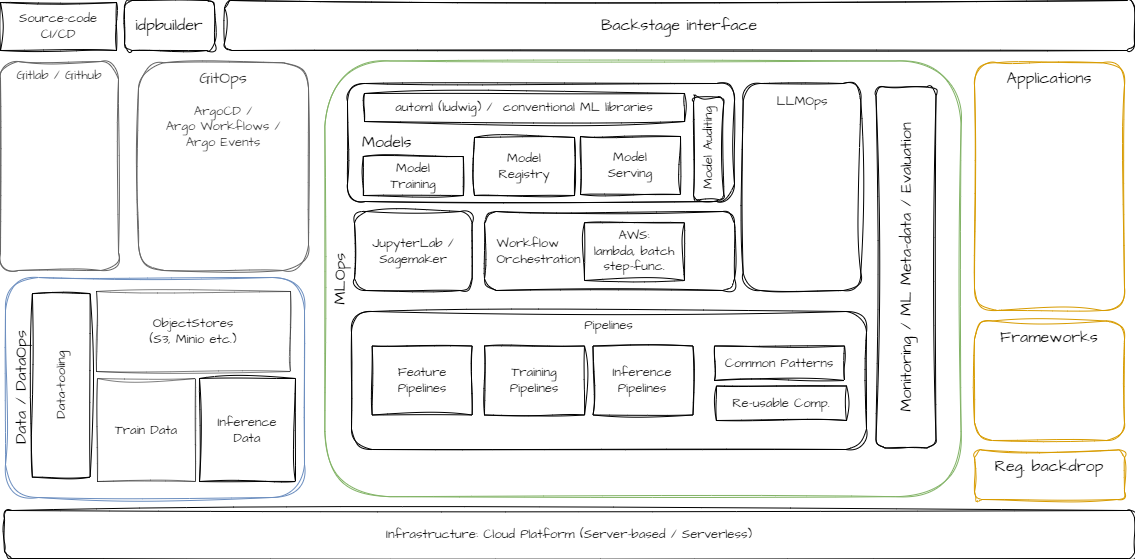
For organisations with geographically spread businesses, or indeed private-equity firms with disparate portfolio companies ripe for collaboration in machine-learning, then establishing one of these platforms centrally and hosting it in the cloud for each business to access their own tech artifacts securely, could be a good solution to seeding the organisation with a culture towards machine-learning more broadly.
Let’s not get ahead of ourselves though. We need to think about what other primitives need to be in place before a solution like Backstage can thrive. Let’s address some of the components that sit under Backstage in our simplified system in Figure 1.
DevOps, GitOps, MLOps … How Did We Get Here?
The DevOps (a portmanteau of Development and Operations) movement spawns from collaboration between previously distinct software development and IT operations camps. It brought with it greater efficiencies as developers took on responsibilities for both writing and running their software. As part of the DevOps approach, pipelines for Continuous Integration and Continuous Delivery (CI/CD) that picked up the latest changes (in code), ran unit tests, built the software artifacts, ran integration tests, and finally deployed the change to production in tightly-controlled stages with rapid rollback if needed. This allowed for multiple deployments of software each day, compared to the monthly or even quarterly release cycles typical prior to DevOps.
GitOps, which itself grew out of the DevOps culture, relies on a model where the operating environment synchronizes its state directly from Git (using the pull principle), where configuration must be completely versioned in Git (infrastructure-as-code). The deployment in the operating environment is triggered by a continuously executed “reconciliation loop”, which detects all deviations from the target state and undertakes a convergence process from the current state to that target. This approach mimics and indeed leverages the kubernetes control-plane based architecture, something I’ll elaborate on below.
Machine-Learning (ML) is now having its “DevOps” moment. Like DevOps, the MLOps (Machine Learning Operations) approach attempts to formalize near-automatic pipelines for the model lifecycle, from data collection, data preparation, and data wrangling, to model training, model evaluation, and model deployment to model monitoring and then back again for model updates. For a thorough overview of MLOps, have a read of this2 paper. Our discussion here will remain a little higher-level, in the spirit of our objective of setting out an outline for an overall AI / ML strategy.
Platforms for Provisioning MLOps
In pursuing an MLOps (machine learning operations) solution for usage in an investment research context, I’ve experimented with many different tools in what has become a very crowded space. Many of these tools are the same technologies, repurposed for a new set of tasks - think vector databases. Nevertheless, combining a mix of these tools in a modular way, while limiting the cognitive overload for developers that now have to contend with new complexities that micro-services and cloud-native technologies have unleashed, is challenging.
I’ve tended to follow the well-beaten track of open-source solutions and many of these pervade in the most innovative parts of the ecosystem, but hosting them in conjunction with eachother generally requires you to immerse yourself in the world of kubernetes, which brings with it a whole other set of technical challenges.
The alternative is to go all-in with cloud-solutions, where the likes of AWS offer a suite of pre-built machine-learning tools, but these, at scale, can become very expensive.
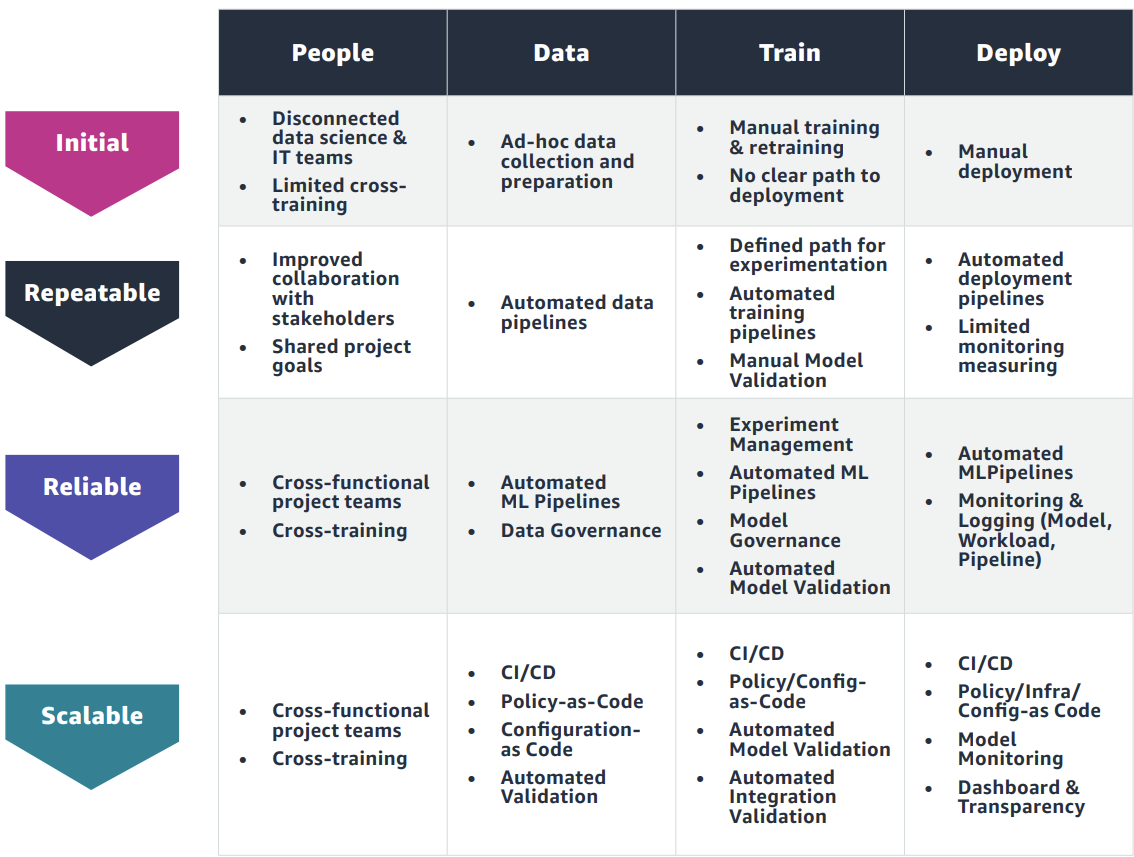
The stage of MLOps maturity, something I introduced in the first blog of this series, has an important bearing on the sophistication of the solution too. In the Initial phase, disparate tooling used for different parts of the value-chain doesn’t all have to fit seamlessly together. There are more manual interventions in the chain to get things working. However, by the Scalable phase, everything needs to be fully integrated and automated.
There’s a thorough review of the MLOps tooling landscape from Neptune.ai3 where they review 90 tools across 17 categories. An important take-away from the article is the number of open-source solutions that continue to thrive in this space. The modus operandi seems to be one to lure developer interest via open-source and then upsell users to selected enterprise features and offer support.
An organisation’s size could also be a determinant of the complexity of a solution and whether it is Saas or self-hosted. At one end of the range are companies experimenting with ML models or just starting to scale their first few deployments. At the other end are businesses that need powerful capabilities to develop and operate sophisticated ML models in production that drive mission-critical business applications deriving value from massive amounts of harvested data.
A common thread underpinning most of these solutions is that they all mostly leverage containerising workloads, a pivotal technology introduced by Docker way back in 2013. The ubiquity of containers then drove the industry towards solutions around orchestrating these containerised components, where it seems the consensus has largely coalesced around Kubernetes5 as the preferred technology upon which to build platforms, even ones capable of running across different cloud providers.
Internal Developer Platforms
While cloud native drove huge improvements in areas like scalability, availability and operability, it also meant setups (applications or running workloads) have became a lot more complex. Expecting developers to have deep knowledge around trouble-shooting code run on cloud-based clusters makes them less productive. Using the lingo, it’s not realistic that every developer (or data-scientist, in our context) can be full-stack. Enabling a team of developers (or data-scientists) to better operate in the cloud but retaining high-enough levels of controls around meeting a given security posture has driven a shift towards what is commonly referred to as ‘platform engineering’.
The open-source IDP (internal developer platform) I have most experience with is Backstage, as per Figure 1, where it’s used as a front-end to control running existing workflows and creating new ones (via argo-workflows). I’ve included a one-pager on key features of that solution below, so I’m not going to elaborate too much here except to say that it is a versatile solution that offers a single pane-of-glass that sits within an organisation allowing users to document and control any resources running either internally or across various cloud-providers. As you can see, data-science oriented businesses like Zalando6 have used this platform as the basis for building-out their whole MLOps stack.
One of the easier ways I have found to get up-and-running with Backstage, in conjunction with other core operating components (ArgoCD, Gitea etc..) is to leverage the idpbuilder tool. We have a separate one-pager on that below (see other tab), but in short it enables you to develop IDPs locally, running them initially on a kind cluster, allowing for debugging combining various components together ahead of a production-grade deployment on a larger cloud-based cluster. That local-to-cloud handover isn’t quite seamless yet, but the tool is very promising. Various stacks (combinations of tools) are contained at github.com/cnoe-io/stacks, allowing new users to get a sense of the capabilities.
Onyxia Datalab is another interesting open-source platform for data-science developed by INSEE, the French National Institute of Statistics and Economic Studies. It resembles Backstage in part, especially Service Catalog, which is essentially a libary of tooling as helm-charts, that get launched into a kubernetes environment on your users’ behalf. They have control allocating RAM, CPU and GPU to specific containers. The system is already tightly-integrated with S3 for data and Vault for secret management. For teams that have restrictions on exposing their data to cloud-based Saas systems, this might be an ideal proving-ground system for intial proof-of-concept work.
Importance of a fast Feedback Loop
In addition to the MLOps platform solutions, as we have learned, there are many other Saas7 offerings that, akin to idpbuilder, offer this ‘develop locally, deploy anywhere’ hybrid capability. However, while idpbuilder is concerned with running-up technology stacks, these new-generation MLOps Saas solutions are all about creating encapsulated workflow jobs or pipelines, often defined in Python, utilising some @decorators to bring special functionality, like specifying cloud-based assets such as container runtimes with GPU access or defining a serverless cloud-based function (such as AWS Step Functions) to perform some batch job. I’m most familiar with Metaflow, but for a deeper dive into comparable solutions, have a look here8.
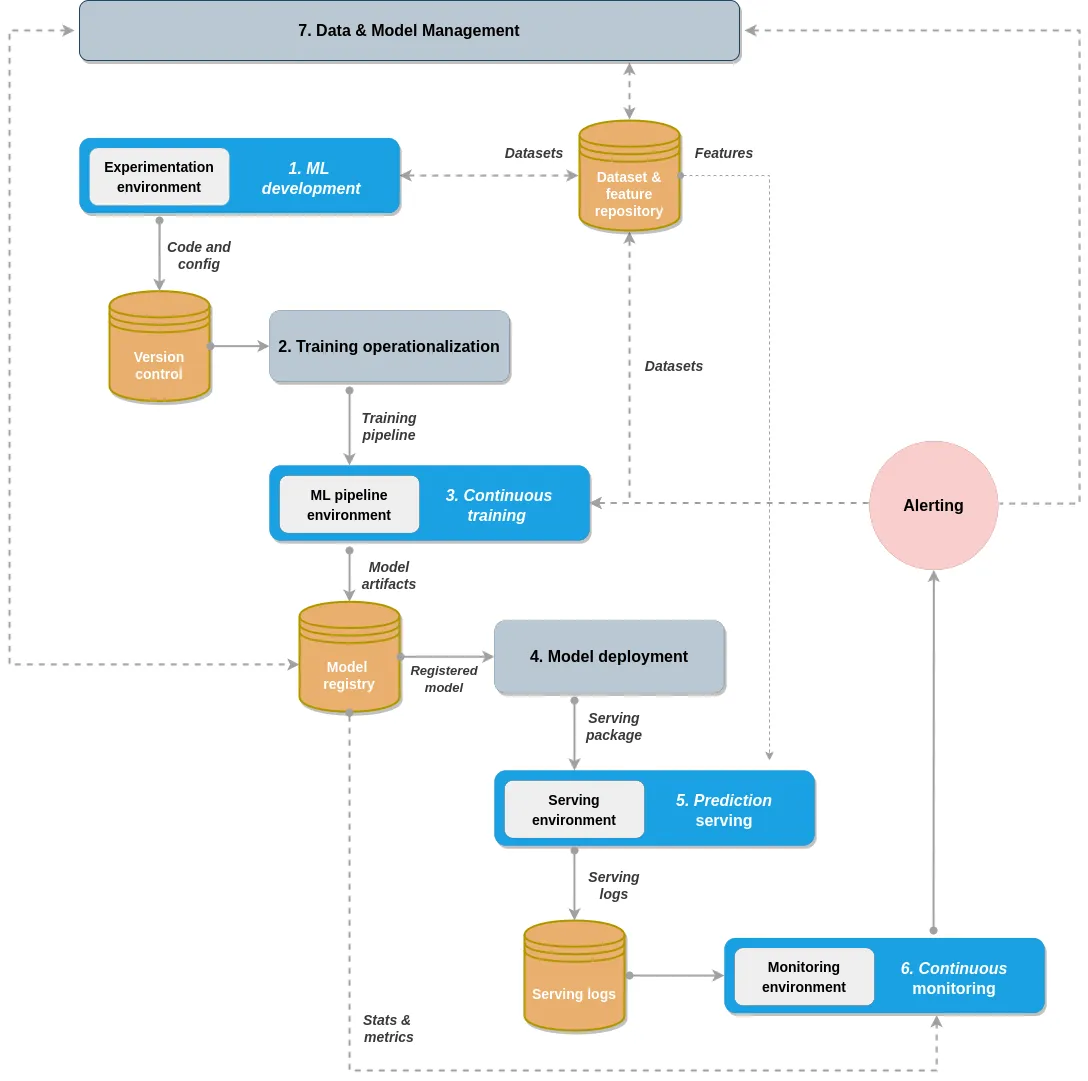
What each of these solutions promise is an ability to build and debug these pipelines locally and then deploy them to run on more robust, more available or faster remote compute. Particularly in this era of LLM application development, none of us has much access to local GPU, so its imperative we have a way of running pipelines efficiently, often in a distributed way. Figure 3 depicts a typical 7-step MLOps process that often forms a working ML system. Generally speaking, the idea is to be able to get each of the steps working efficiently, with as short-as-possible feedback loops, so that developers can fix or refine those parts accordingly.
On certain cloud-based infrastructure set-ups, let’s say we have Kubeflow running on an EKS cluster, it can sometimes take 30 minutes to have a stable running cluster and then troubleshooting jobs, in particular those looking to distribute workloads across multiple workers in parallel, can be a time-consuming and frustrating process.
I have been recently prototyping with one of the new-breed of serverless GPU platforms called Modal. It’s well worth your time spending 30 minutes watching this MLOps on Modal9 run-through, rather than me trying to explain things here. The bottom-line is that their infrastructure is laser-focused on this fast feedback loop concept, in terms of being able to run workloads fast in a distributed way, but only having to pay for the seconds of actual GPU-usage, as opposed to you having to secure, then manage a fleet of VMs with GPUs. You can have deployments on web endpoints that will only start on receipt of an inference request, ensuring compute spend is kept to a minimum. There’s another good run-through here10, especially pertaining to running multiple workloads in parallel for faster execution.
MLOps Iterative Process
These are the actual processes involved in performing machine-learning operations, as opposed to the components used for MLOps. This workflow is modelled on the Practioners Guide to MLOps11 from Google. The processes can consist of the following:
- ML development concerns experimenting and developing a robust and reproducible model training procedure (training pipeline code), which consists of multiple tasks from data preparation and transformation to model training and evaluation.
- Training operationalization concerns automating the process of packaging, testing, and deploying repeatable and reliable training pipelines.
- Continuous training concerns repeatedly executing the training pipeline in response to new data or to code changes, or on a schedule, potentially with new training settings.
- Model deployment concerns packaging, testing, and deploying a model to a serving environment for online experimentation and production serving.
- Prediction serving is about serving the model that is deployed in production for inference.
- Continuous monitoring is about monitoring the effectiveness and efficiency of a deployed model.
- Data and model management is a central, cross-cutting function for governing ML artifacts to support auditability, traceability, and compliance. Data and model management can also promote shareability, reusability, and discoverability of ML assets.
Data-centric approach to MLOps
Proprietary data is often referred to as the ‘secret sauce’ and those organisations who best harness it with ML will capture disproportionate economic value. A data-centric approach to building ML systems emphasizes data management over incremental modeling improvements. Synthetic data generation and data labeling (often performed by LLMs), validation, auditing, and ML monitoring have all become important parts of the MLOps process. The data-centric approach emphasizes data quality and monitoring as an essential part of building production ML systems.
The next blog-post in this series will be delving into all things DataOps. Having some strategy around data-management, automated builds with gitops patterns, containerising workloads and using some form of orchestration can get you a good distance towards a well-functioning blueprint for a system that can work universally for different industry client-types.
Footnotes
Backstage, An open source framework for building developer portals.↩︎
Machine Learning Operations (MLOps): Overview, Definition, and Architecture, Kreuzberger, Kuhl, and Hirschl, KIT and IBM, 2022↩︎
MLOps Landscape in 2024: Top Tools and Platforms, Stephen Oladele, September 2024↩︎
derived from: MLOps: Emerging Trends in Data, Code, and Infrastructure, Venture Capital and Startup Perspective, June 2022↩︎
K8s Is Not the Platform – Or Is It and We All Misunderstood?, Stefan Schimanski, Upbound, Nov. 2023↩︎
Sunrise: Zalando’s developer platform based on Backstage, Lessons learned from adopting Backstage as Developer Platform at Zalando, Aug. 2023↩︎
MLOps Landscape in 2024: Top Tools and Platforms, Stephen Oladele, September 2024↩︎
ZenML v. Flyte v. Metaflow, Ankur Tyagi, January 2025↩︎
MLOps on Modal, Charles Frye presenting on training an SLM using Modal↩︎
Orchestrating Flexible Compute for ML with Dagster and Modal, with discussion of
Function.starmap()to run multiple parallel workloads↩︎Practitioners guide to MLOps:, A framework for continuous delivery and automation of machine learning, Google, May 2021↩︎
Citation
@misc{mccoole2025,
author = {{Colum McCoole}},
title = {3. {Platform} {Engineering} for {Evolving} {AI} / {ML}
{Solutions}},
date = {2025-02-14},
url = {https://analect.com/posts/ai-strategy-series/3-gitops-platforms-to-mlops/},
langid = {en-GB}
}